Continuous model
In this section, we present the overall architecture of the continuous model, as well as several results from tasks like style transfer, latent interpolation, and integration within two framework (offline and realtime).
Continuous model’s architecture
The continuous model is itself composed of two submodels, a mel-spectrogram variational autoencoder, and a mel-spectrogram to waveform model (we use a modified melGAN). The total architecture can be found on the figure below. The mel-spectrogram variational autoencoder is a fully convolutional neural network composed of several stacked layers for both the encoder and the decoder. We have added a Kullback-Leibler divergence between the encoder’s output and a standard Gaussian as a prior regularization, in order to enforce local smoothness inside the latent space. We also added an adversarial regularization to make the latent space agnostic with relation to loudness, so that it can be either computed deterministically (training / inference) or controlled manually (inference).

In order to make the model compatible with a realtime application, we’ve designed a specific convolutional module wrapping a standard convolution module with a circular buffer mechanism. The continuous model can be downloaded here
Offline interface
We provide a graphical interface in order to ease the process of using deep learning models for general audio manipulation.
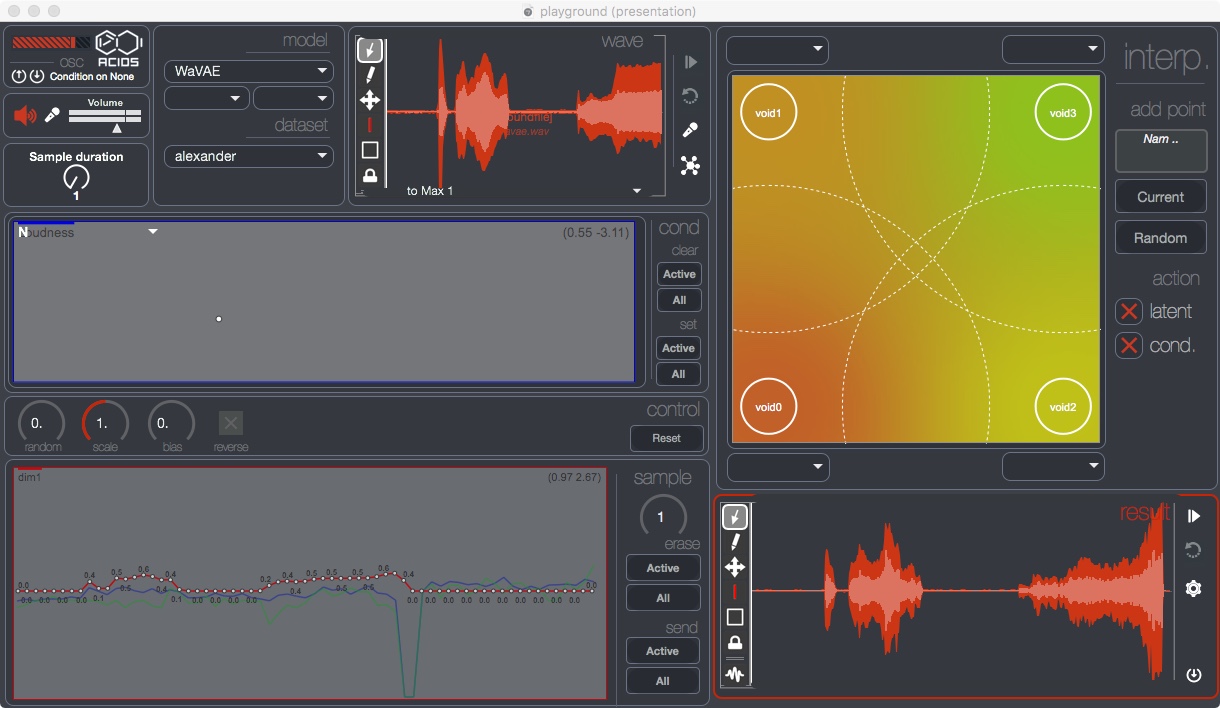
This interface expose the latent path infered by the model from a input audio sample. Several mathematical operators are available to scale, randomize, bias or reverse the latent path, as well as a curve editing window, allowing direct modification of each dimension. We also provide an interpolation pseudo-plane, allowing a weighted linear interpolation between four latent paths. The following examples have been generated using this interface.
Interpolation
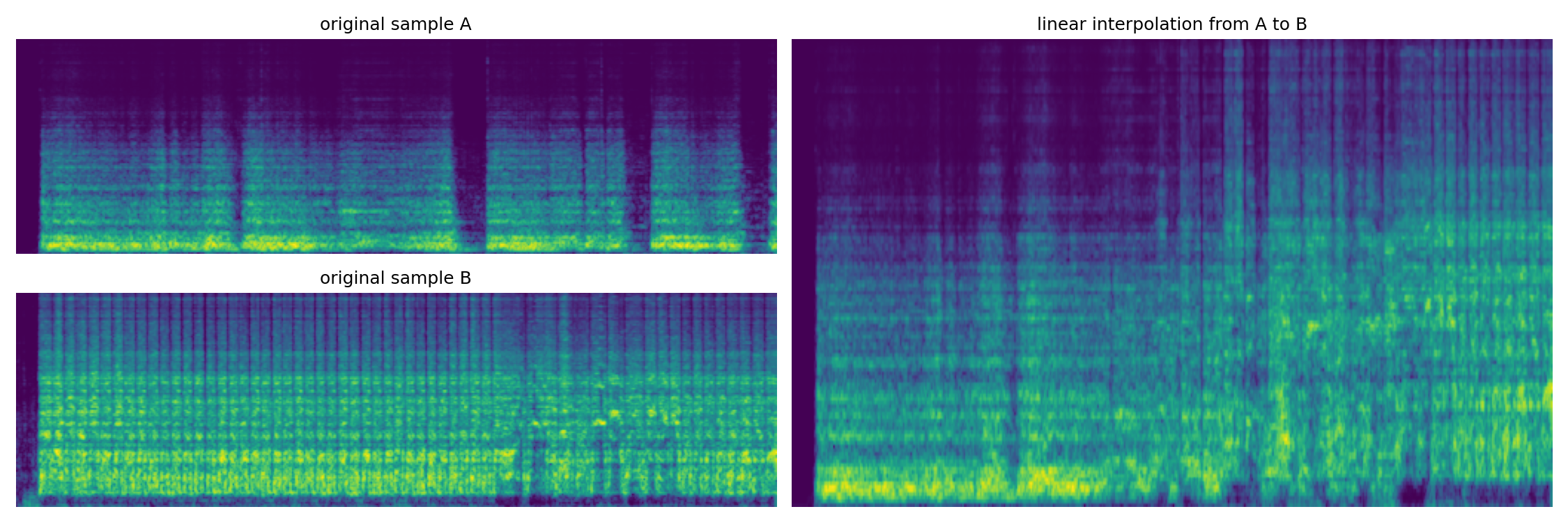
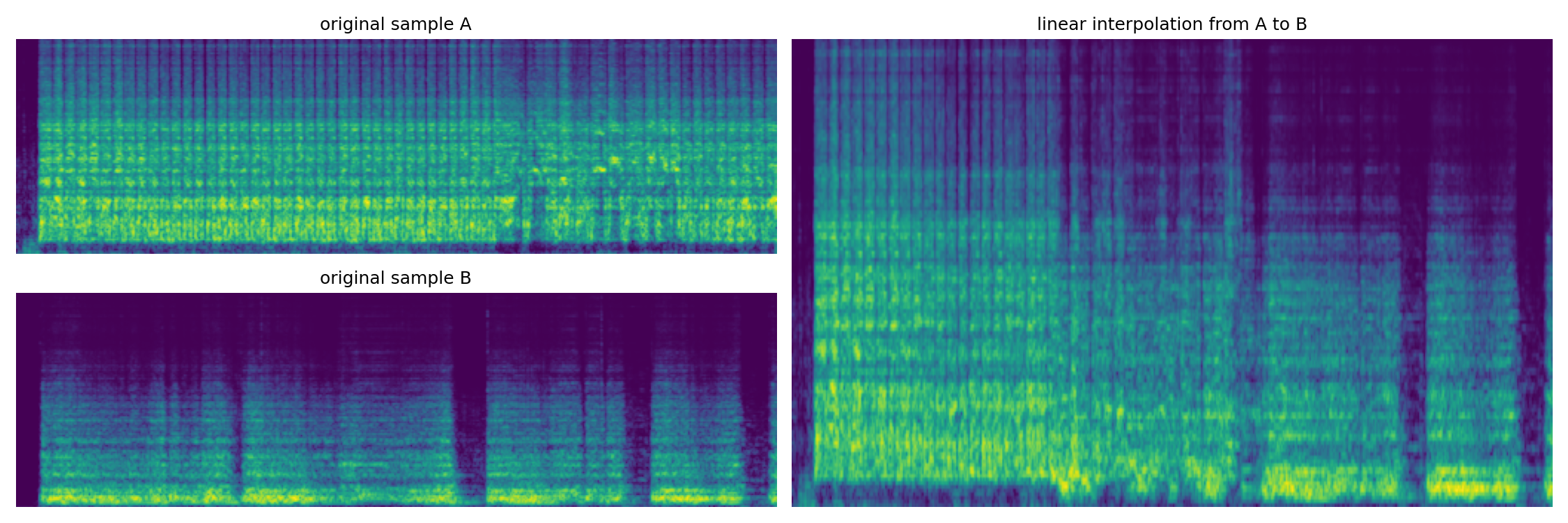
Here we show how the continuous model can perform a linear interpolation between two input audio samples. Both samples are first encoded into a latent path z_a and z_b of size N, then we compute an interpolated path:
z[n] = z_a[n] * (1 - n/N) + z_b * (n/N)
The following examples show the melspectrogram corresponding to the original samples and the interpolated ones. The audio examples will play in order sample A, sample B and the interpolation.
Dataset: Strings
Dataset: Strings
Style transfer
By giving a model an input sample that is out of the domain on which it has been trained, we can get some sort of style transfer:
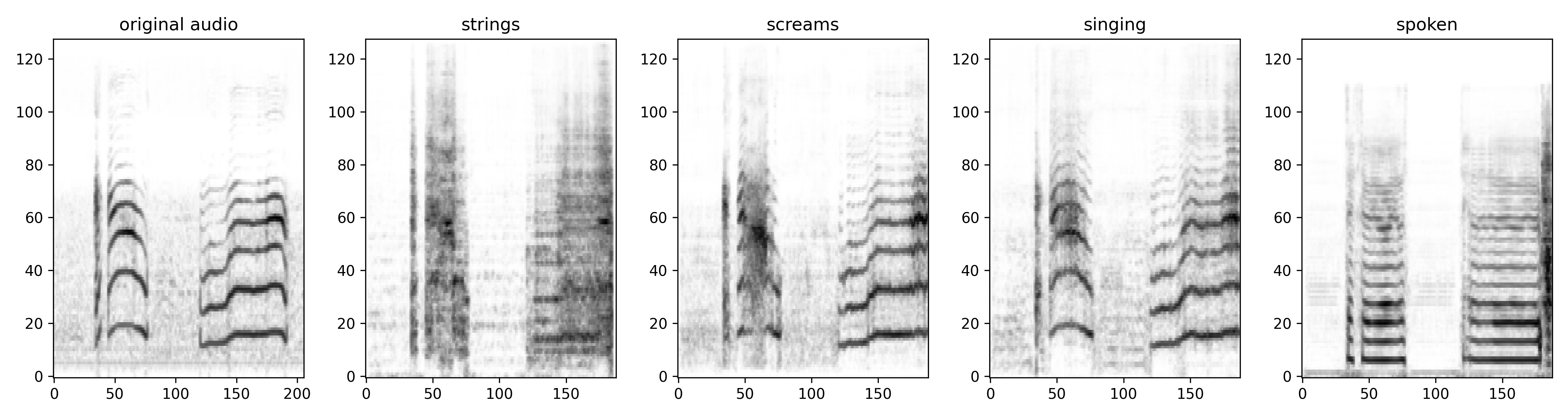
| Domain | Audio |
|---|---|
| Original | |
| Strings | |
| Screams | |
| Singing | |
| Spoken |
Realtime interface
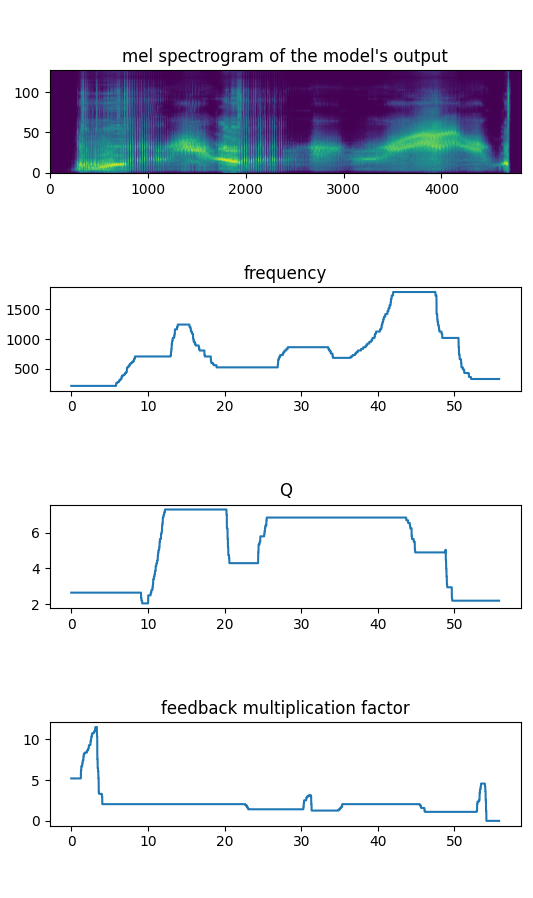
Feedback shaping
Using our realtime puredata implementation, we can easily feed the model with its own output, filtered with a bandpass filter defined by its center frequency f and quality factor Q, as described in the figure below.
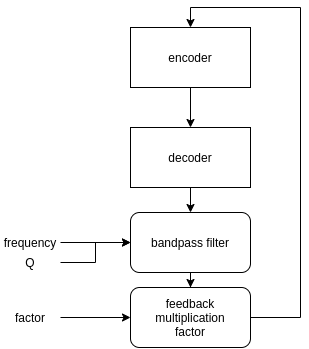
This gives a way to shape the model’s generation based on a user-defined spectral shape. The puredata patch used to produce the following example is the one below
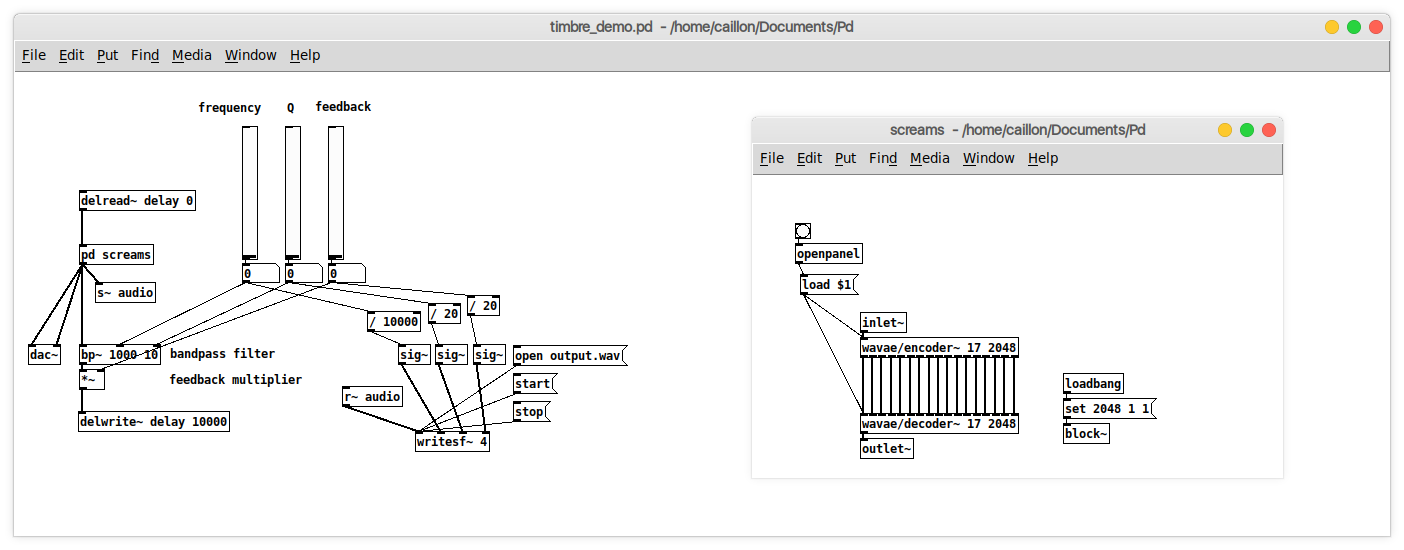
Dataset: Screams