Generative variational timbre spaces
Generative timbre spaces with perceptually-regularized variational audio synthesis
Generative variational timbre spaces
This repository describes the additional material and experiments around the paper “Generative timbre spaces with variational audio synthesis” submitted at the 2018 DaFX Conference.
Timbre spaces have been used in music perception to study the perceptual relationships between instruments based on dissimilarity ratings. However, these spaces do not generalize, need to be reconstructed for each novel example and are not continuous, preventing audio synthesis. In parallel, generative models have aimed to provide methods for synthesizing novel timbres. However, these systems do not provide an explicit control structure, nor do they provide an understanding of their inner workings and are usually not related to any perceptually relevant information. Here, we show that Variational Auto-Encoders (VAE) can alleviate all of these limitations by constructing variational generative timbre spaces. To do so, we adapt VAEs to create a generative latent space, while using perceptual ratings from timbre studies to regularize the organization of this space. The resulting space allows to analyze novel instruments, while being able to synthesize audio from any point of this space. We introduce a specific regularization allowing to directly enforce given perceptual constraints or simi- larity ratings onto these spaces. We compare the resulting space to existing timbre spaces and show that they provide almost similar distance relationships. We evaluate several spectral transforms as input and show that the Non-Stationary Gabor Transform (NSGT) provides the highest correlation to timbre spaces and the best quality of synthesis. Furthermore, we show that these spaces can generalize to novel instruments and can generate any path between in- struments to understand their timbre relationships. As these spaces are continuous, we study how the traditional acoustic descriptors behave along the latent dimensions. We show that even though descriptors have an overall non-linear topology, they follow a locally smooth evolution. Based on this, we introduce a method for descriptor-based synthesis and show that we can control the descriptors of an instrument while keeping its timbre structure.
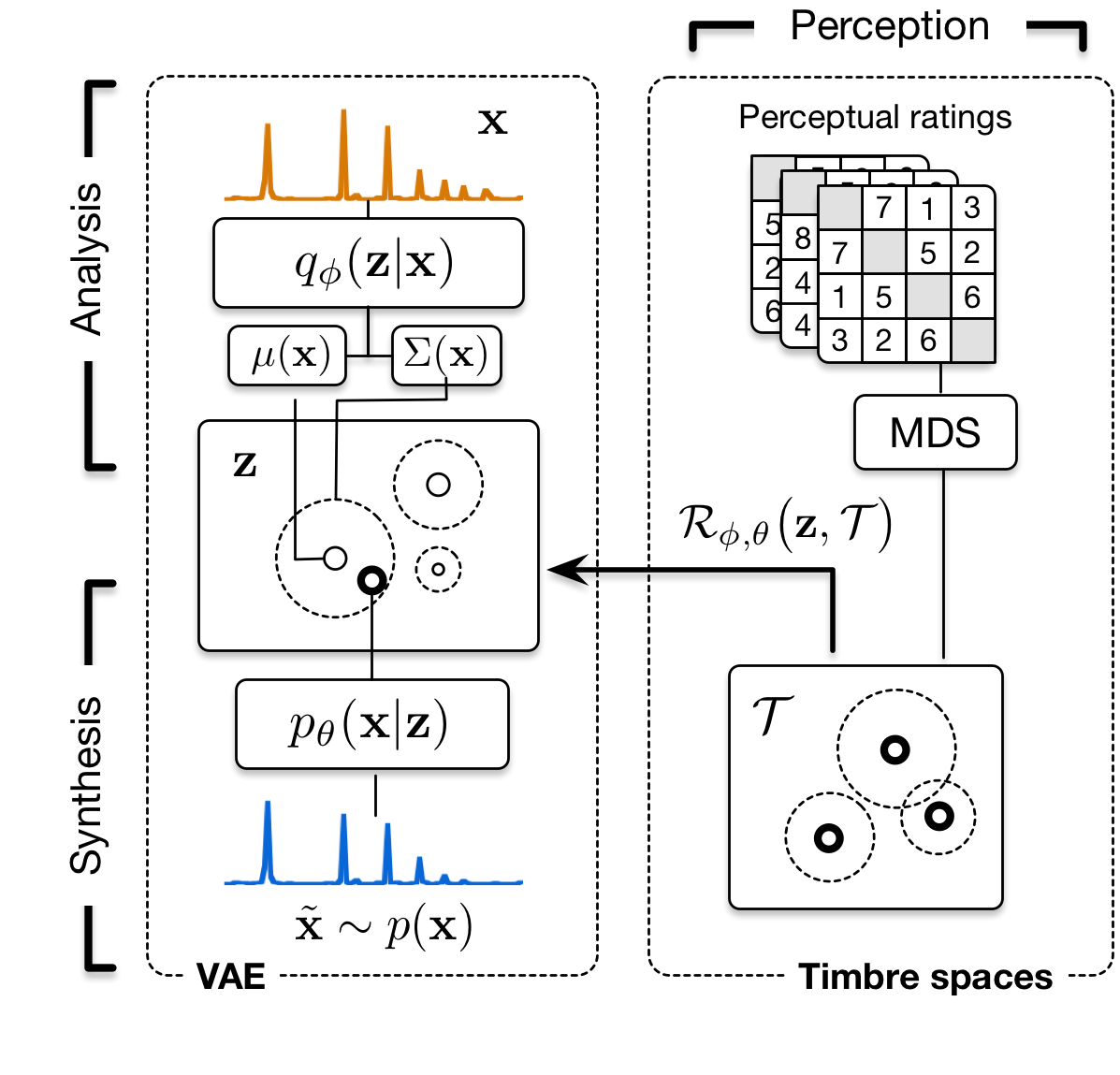
Here, we directly embed the exposed elements
- Animations of descriptor space traversal (topology)
- Audio examples of synthesized paths in the space
- Detailed analysis of perceptual inference abilities
- Additional data and information
Otherwise, you can directly download and parse through the different sub-folders of the docs/ folder on GitHub to view all of these informations.
Descriptor space animations
As detailed in the paper, the space obtained through variational learning are continuous and we can directly sample from these. Therefore, this property allow us to define a dense sampling grid across the space, from which we can generate the spectral distributions. Then, we compute the corresponding descriptors of the distributions at each point of the sampling grid. This allows to plot the continuous evolution of the descriptor topology across the latent spaces. Here, we compare between different models and also provide all topologies across X, Y and Z axes.
Model topology comparison
We compare the topology of different descriptors along the X axis between the vanilla (top) and student-regularized (bottom) VAE learned on orchestral instruments.
Click here if you want to see more space comparisons ...
Complete model topology
Here we provide the complete topology of a student-regularized latent space, by evaluating the centroid, flatness, bandwidth, loudness and rolloff across the X (top), Y (middle) and Z (bottom) axes of the PCA-transformed latent space
Centroid
Click here if you want to see more full descriptor space topologies ...
Synthesis paths sounds
As detailed in the paper, we can synthesize a distribution from any point in the latent space. However, to evaluate the effect of our perceptual regularization, we investigate what happens by synthesizing paths between selected instruments. To synthesize the audio between two instruments, we use the position of a given instrument in the latent space and select randomly another instrument to act as an ending position . Then we perform an interpolation between these positions in the latent space, and at each interpolated point , we use the decoder of the VAE to generate the corresponding distribution. We can either use a linear, spherical or expressive interpolation
Linear
Spherical
Expressive
To better understand how these different interpolation work, here are two video animations that shows the different paths (spherical or expressive) between the Violin and the Clarinet in latent space, and the corresponding distributions that are being generated.
Spherical
Expressive
Spherical or expressive interpolations
We start by comparing spherical or expressive interpolations between instruments in the latent spaces. While listening to these examples, keep in mind that all these models have been trained with a single spectral frames per instrumental note !
| Origin | End | Spherical | Expressive |
| Bassoon | Clarinet Bb | ||
| Clarinet Bb | Alto Sax | ||
| French Horn | Trombone |
Next, we provide examples, where the pitch between different instruments is allowed to change, which generates even more complex audio distributions, while remaining perceptually smooth in their evolution.
Bassoon - Violoncello
English Horn - Violin
Violin - Alto Sax
Oboe - Clarinet Bb
Alto Sax - Bassoon
On the flatness of the manifold
We made an interesting discovery while working on the synthesis of paths between different instruments. In fact, it appears that performing a linear or spherical interpolation results in the exact same spectral distribution. This seems to underline the overall flatness of the audio manifold in latent space.
Expressive and experimental interpolation
By performing some modifications (such as increasing or decreasing translation) on a given path between different instruments, we can obtain interesting and creative types of sounds, as exemplified by the following audio examples
Perceptual inference abilities
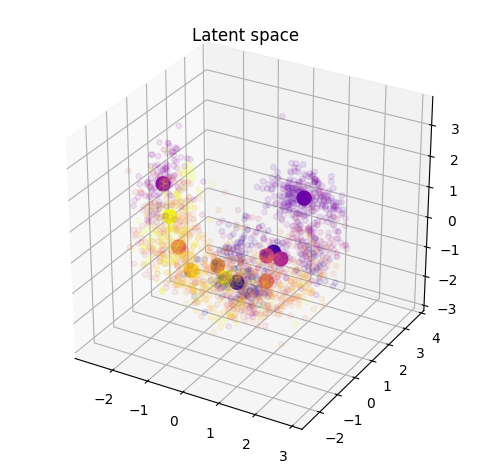
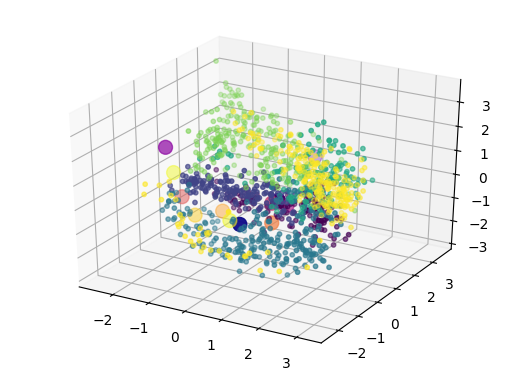
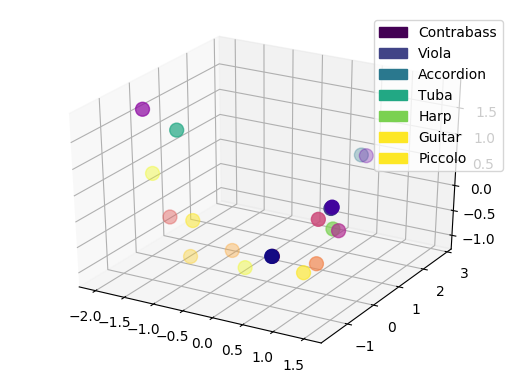
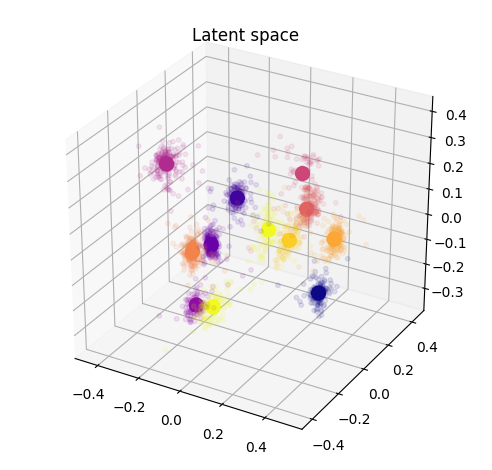
As detailed in the paper, we can perform a projection inside this space of novel instruments, that were not even part of the original studies (nor the overall VAE training). Here, we show that the projection appears to be coherent with the potential perception of these instruments. We display the original latent space (top, left), and show how new instruments are projected in this space compared to the distribution of original instruments centroid (top, right). We then show the comparison of either only centroid (bottom, left) or all points (bottom, right)
Comparing regularized and vanilla
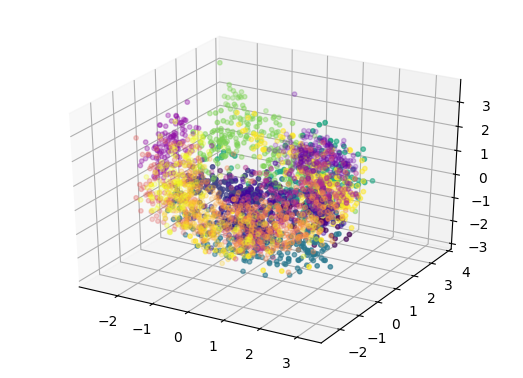
Vanilla VAE
As we can see, the novel instruments are spread all across the latent space.
Regularized VAE
Oppositely to the Vanilla version, thanks to the regularization the novel instruments are well grouped inside the latent space and seem to be close to logical instruments in terms of perception.
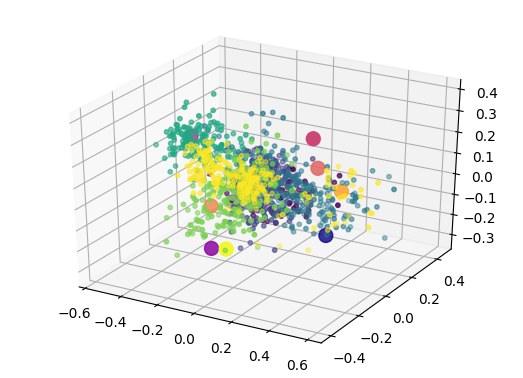
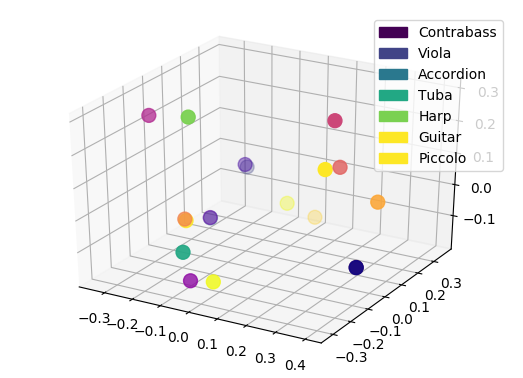
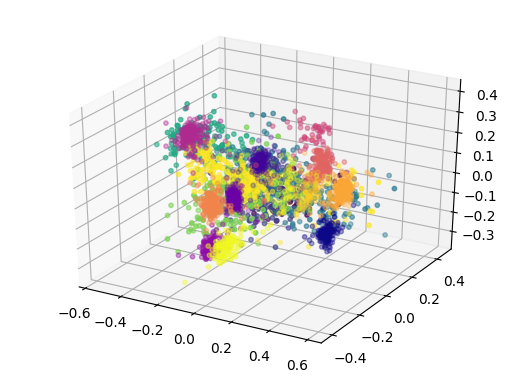
Additional information
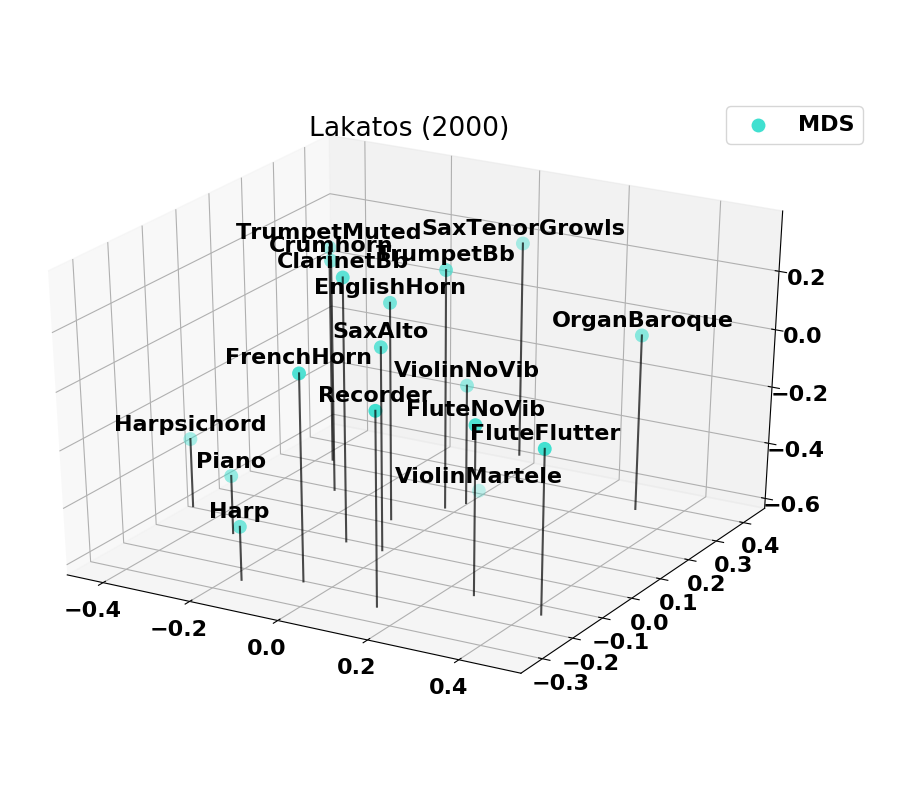
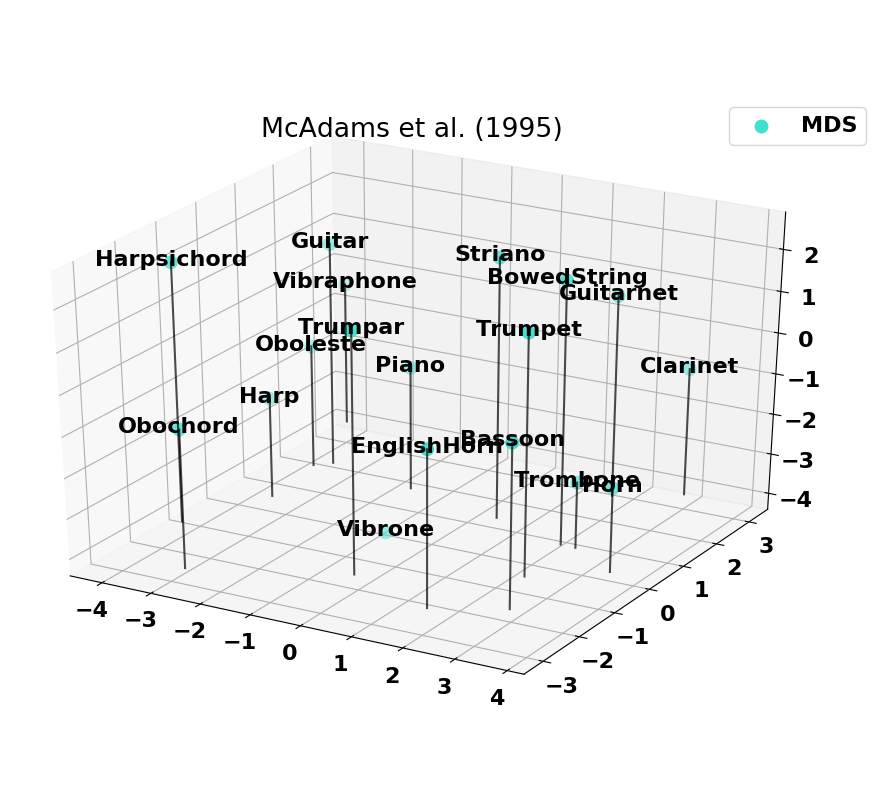
Existing timbre spaces verification
Here we provide information on the timbre spaces that were computed based on the normalized versions of past studies.
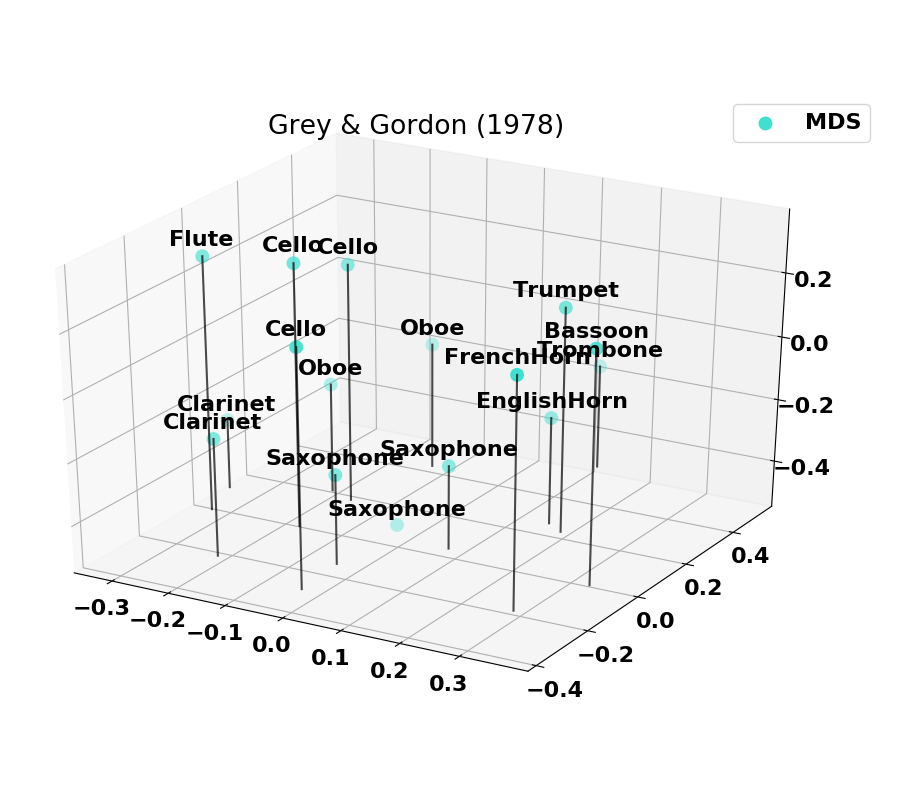
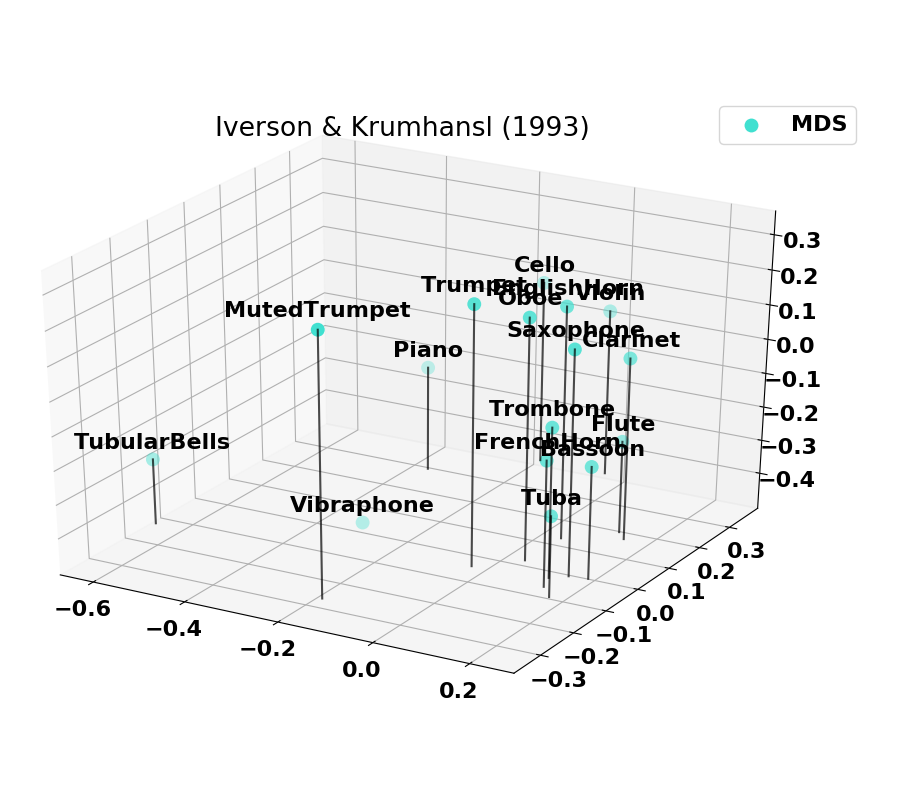
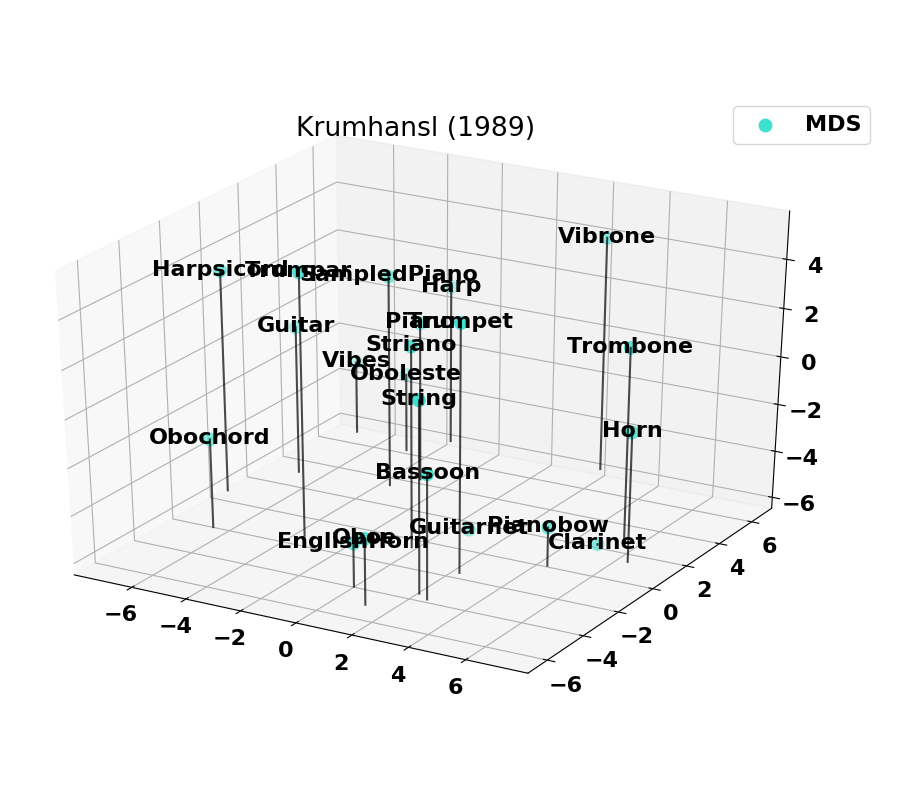
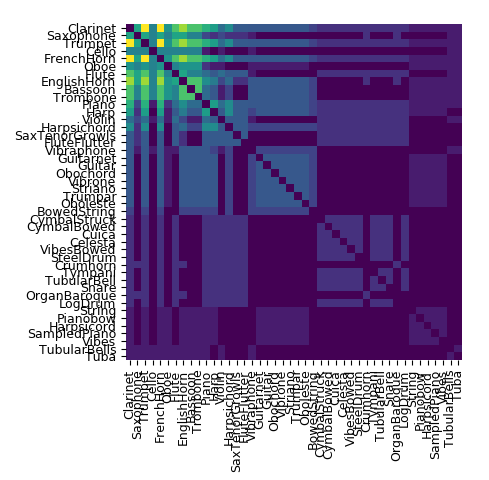
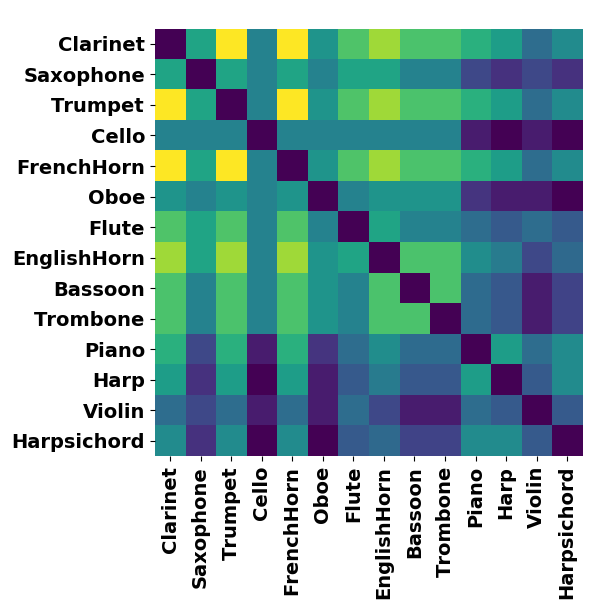
Co-occurences of instruments
The combined set of instruments from past studies is plotted as a set of co-occurences. On the left is the set of all instruments combined and on the right is the 14 instruments with the highest number of co-occurences. Note that the Harp and Harpsichord have some co-occurences missing (notably with the Oboe), which explains why we removed them from the final set.
Code
The full code will only be released upon acceptance of the paper at the DaFX 2018 conference and will be available on the corresponding GitHub repository